
Bij deze cursus zijn ook een aantal oefenopgaven gemaakt, deze vind je onder de cursus.
Als je van deze cursus gebruik maakt, willen we je vriendelijk vragen te laten weten wat je er van vond:
- Geef eventuele foutjes aan;
- Zijn de onderdelen soms onduidelijk, of net erg helder?
- Ontbreken er volgens jou stukken, of heb je suggesties?
- ...
---------------------------------------------------------------------------------------
[microcursus]: WAT IS DNA? (basis)
Trefwoorden: DNA RNA nucleotide helix translatie transcriptie codon proteïne eiwit aminozuur
Auteurs: Mrtn , Klintersaas , Jan van de Velde
1. Historie en belang van DNA
1.1 Een stukje wetenschapshistorie
DNA werd door de meeste biologen al rond de Tweede Wereldoorlog als de drager van erfelijke eigenschappen gezien. Het mechanisme was echter niet bekend rond die tijd. De chemische structuur en ruimtelijke ordening van DNA werden in 1953 ontdekt door de wetenschappers James Watson en Francis Crick. Hiervoor hebben ze onder andere gebruikgemaakt van röntgenkristallografieopnamen van DNA, gemaakt door Rosalind Franklin (een naam die in verband met DNA helaas te weinig genoemd wordt).
 (afb. 1)
(afb. 1)V.l.n.r. Rosalind Franklin, James Watson en Francis Crick
In dat DNA is de informatie opgeslagen waarmee de cel proteïnen (eiwitten) kan maken.
1.2 Eiwitten aan de basis van het leven
Bij het woord eiwit denk je misschien eerst aan een gekookt eitje, maar daarmee onderschat je het belang ervan. Eiwitten vervullen onmisbare functies in elk levend organisme. Een overzicht met enkele voorbeelden:
- Chemische omzettingen: Enzymen regelen chemische reacties (katalysefunctie). Dankzij enzymen wordt ons voedsel afgebroken tot de simpele bouwstoffen die in ons bloed kunnen worden opgenomen en getransporteerd naar waar ze nodig zijn;
- Structuur: Keratinestructuren zoals haar en nagels of collageenstructuren zoals in de huid geven cellen en weefsels structuur en vorm. Deze structuren kunnen ook dynamisch zijn: ze kunnen ervoor zorgen dat de cel van vorm verandert (bijvoorbeeld het samentrekken van spiercellen), ze maken de celdeling mogelijk en ze dragen ertoe bij dat sommige cellen zich kunnen verplaatsen;
- Transport: Hemoglobine in de rode bloedlichaampjes zorgt voor transport van zuurstof in het bloed. Zogenaamde ionenpompen zorgen voor het transport van ionen in en uit de cel;
- Communicatie: Hormonen zorgen voor de communicatie tussen cellen op afstand. Signaaleiwitten zorgen voor de communicatie binnen cellen. Eiwitten zijn ook onmisbaar voor het doorgeven van signalen in de zenuwen;
- Regulatie: Allerhande eiwitten regelen zowat alle processen in de cellen;
- Beveiliging: Antilichamen maken ziekteverwekkende vreemde eiwitten onschadelijk. Bloedstollingsfactoren zijn de EHBOers van het lichaam;
- Brandstof: Ten slotte kunnen eiwitten in geval van nood als brandstof dienen.
(Die set aminozuren zou je je kunnen indenken als een set van een twintigtal verschillende onderdelen (radertjes, schroefjes, palletjes, asjes,...). Door enkele tientallen tot duizenden van die onderdelen op verschillende manieren te combineren kun je een bijna oneindig aantal verschillende machines bouwen, elk met een eigen specifieke functie.)
Weetje: Het grootste bekende proteïne tot heden is titine (connectine), opgebouwd uit 26926 aminozuren.
Als wij dierlijke of plantaardige eiwitten eten kunnen we er niet zo veel mee in die vorm. In het spijsverteringskanaal worden die eiwitten daarom afgebroken tot de losse aminozuren. (Een aantal van die aminozuren kan ons lichaam desnoods ook zelf aanmaken. Er zijn er ook acht die we niet zelf kunnen maken en we dus per se met ons voedsel moeten binnenkrijgen; dat noemen we de essentiële aminozuren.) De losse aminozuren worden door het bloed naar een cel getransporteerd.
In de cel is het dan uiteindelijk het DNA dat bepaalt in welke volgorde aminozuren aan elkaar worden geknoopt zodat er een eiwit ontstaat met een bepaalde functie. DNA bevat dus de bouwplannen van al die verschillende eiwitten, het is eigenlijk een hele lange rij codekarakters.
 (afb. 2)
(afb. 2)Eiwitten zijn onmisbaar voor het levensproces. Ze bepalen hoe een levend wezen eruitziet en hoe het werkt. Die informatie moet mee van de ene generatie naar de volgende. Daarom noemen we het DNA de drager van de erfelijke eigenschappen. Verander iets in de code van het DNA, en een organisme ziet er anders uit, of werkt anders. Als we zoiets met opzet doen, dan heet dat 'genetische modificatie'.
2 De opbouw van DNA
Hieronder gaan we eens steentje voor steentje een DNA-molecuul opbouwen. Laat je niet afschrikken door de structuurformules; op het eerste gezicht ziet het er vreselijk ingewikkeld uit, maar als je goed kijkt zul je zien dat die eigenlijk steeds sterk op elkaar lijken, alles heeft dezelfde basisstructuur en herhaalt zich steeds. We geven die structuurformules erbij om te laten zien waarom DNA eruitziet en kan functioneren zoals het dat doet.
2.1 De nucleotiden
DNA staat voor Deoxyribo Nucleic Acid. Spreek uit: [dee-oxie-riebo nu-klee-ik es-id]. Dit is te vertalen naar DesoxyriboNucleïneZuur. DNA bestaat uit twee in elkaar gedraaide strengen, die elk bestaan uit:
- een ruggengraat (backbone) om alles bij elkaar te houden;
- zogenaamde (stikstof)basen, waarvan de volgorde langs de ruggengraat een code vormt.
Het begint met desoxyribose: een (ringvormig) suikermolecuul met vijf koolstofatomen, waaraan het DNA zijn naam ontleent. De koolstofatomen van de ring worden genummerd met een cijfer en een accent, vanaf het O-atoom. Zo wordt het derde koolstofatoom 3' genoemd. Dit spreek je uit als [drie-accent]. Vanzelfsprekend noemen we het vijfde koolstofatoom (dat buiten de ring ligt) 5':
 (afb. 3)
(afb. 3)Aan koolstofatoom 5 zit een fosfaatgroep. Dat komt er dus zó uit te zien:
 (afb. 4)
(afb. 4)Aan koolstofatoom 1' kan een stikstofbase (een heel wat ingewikkelder molecuul) gekoppeld worden.
Hiermee is de nucleotide compleet:
 (afb. 5)
(afb. 5)DNA bevat maar vier verschillende stikstofbasen: adenine, thymine, guanine en cytosine . Deze worden afgekort met hun eerste letter, respectievelijk A, T, G en C. In structuurformule zien die er zó uit :
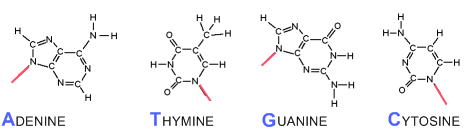 (afb. 6)
(afb. 6)2.2 De nucleotidenstreng
Een ander O-atoom van elke fosfaatgroep kan gekoppeld worden aan het 3'-koolstofatoom van een andere desoxyribosemolecule. Zo kun je duizenden nucleotiden met hun fosfaatgroepen aan elkaar koppelen en krijg je één lange streng:
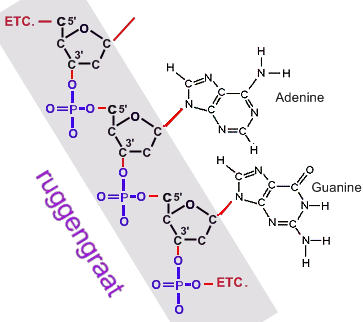 (afb. 7)
(afb. 7)2.3 Twee nucleotidenstrengen koppelen
Tussen de basen van twee strengen kunnen waterstofbruggen worden gevormd. Een waterstofbrug is een niet al te sterk soort binding tussen waterstofatomen en naburige N-, O-, S- of F-atomen. Dat kan niet zomaar lukraak: het moet een beetje passen.
Tussen adenine en thymine kunnen mooi twee van die waterstofbruggen worden gevormd, en tussen guanine en cytosine steeds mooi drie waterstofbruggen. In andere combinaties past dat niet, dus zul je tegenover een adeninegroep nooit een guaninegroep aantreffen. Daarom noemen we A en T, respectievelijk G en C "basenparen" of "complementaire basen".
 (afb. 8)
(afb. 8)Nu je weet hoe één en ander in elkaar zit schakelen we over naar een wat schematischer overzicht:
 (afb. 9)
(afb. 9)In de figuur hierboven zie je de ruggengraat in het paars. De overige kleurtjes zijn de vier basen A, G, C en T.
Je ziet hier op één stukje streng overigens allevier de basen. Dat hoeft zeker niet zo te zijn. Elke volgorde is mogelijk, ook meerdere basen van één soort naast elkaar op één streng. Als je langs één zo'n streng "leest", dan zie je een schier oneindige rij gecodeerde informatie, bijvoorbeeld: C A G C G T A A G C T A G G T C C etc.
Wél kan A alleen maar gekoppeld kan zijn aan T op de tegenoverliggende streng, en G alleen maar aan C (door die waterstofbruggen, weet je nog?). Zo zijn de twee strengen als het ware elkaars negatief . Als je de basevolgorde op de ene streng kent, weet je ook precies de basevolgorde op de andere streng. We zullen later zien dat dat heel handig is om DNA te kopiëren.
2.4 De dubbele helix
Helix: (v.; helices) [<Latijn <Grieks helix (gedraaid)], 1 schroeflijn.
 (afb. 10)
(afb. 10)Zo'n rechte dubbele streng is niet zo stevig. Maar spiraalvormig om elkaar heen gedraaid wordt dat ineens heel anders, terwijl het tóch flexibel blijft. Daarom vormen de twee strengen een dubbele spiraal - met een mooi woord "dubbele helix" - zoals in bovenstaande afbeelding.
2.5 Chromosomen
Het DNA ligt in fragmenten in onze cellen en die fragmenten noemen we chromosomen. Mensen hebben er 23 paren van: in elk chromosomenpaar zit één chromosoom van de moeder en één van de vader. In het totaal dus 23 x 2 = 46 stuks.
Als je al het DNA uit één menselijke cel achter elkaar zou plakken, kom je aan een lengte van bijna twee meter (!). (sommige chromosomen zouden uitgerold al 5 cm lang zijn!!) Ter vergelijking: een typische menselijke levercel is gemiddeld slechts 20 micrometer (0,02 mm) groot. Vergelijk het met een touwtje van 2 kilometer lang dat je in een vingerhoedje moet stoppen. Je kunt je voorstellen dat je het zonder een efficiënte manier van opslag niet kwijt kunt in je cel(kern).
Daarom wordt de dubbele helix op zijn beurt rond eiwitten (histonen) gerold. Een hele serie van die rond histonen opgerolde stukjes DNA wordt dan ook weer in helixvorm opgerold en van heel die helix wordt nóg eens een grotere helix gemaakt. Hier zie je hoe je je dat ongeveer voor moet stellen:
 (afb. 11)
(afb. 11)Zo berg je dus een dubbele streng van in totaal 2 m lengte in stukken op in een celkern.
De totale verzameling van chromosomen in een cel heet een karyotype:
 (afb. 12)
(afb. 12)Je ziet de 23 sets chromosomen, waaronder een set met een X en een Y. Deze twee maken het verschil tussen man en vrouw: dubbel X is een vrouw en een X en een Y maakt een man.
Weetje: Wanneer er iets fout gaat tijdens de celdeling kunnen er afwijkingen ontstaan in het aantal en de vorm van de chromosomen. Dit noemen we chromosomale afwijkingen. Een bekend voorbeeld van een chromosomale afwijking is trisomie van chromosoom 21 (dan heb je er drie keer chromosoom 21 in plaats van twee): dit ligt aan de basis van het syndroom van Down.
Nog een weetje: in mensen is het DNA lineair. Dat wil zeggen dat het een kop en een staart heeft. In bacteriën niet: daar is het circulair (rond). In bacteriën gedraagt het circulair DNA zich als een elastiekje dat je tussen je vingers, tegen elkaar in in elkaar draait. Als je dan de eindjes naar elkaar toe brengt, krult het helemaal op. Dit heet supercoiling.
3 Hoe werkt DNA?
De informatie vastgelegd in het DNA moet dikwijls gekopieerd worden, zodat de informatie niet verloren gaat. En natuurlijk moet de informatie ook kunnen worden gebruikt om die duizenden verschillende onmisbare eiwitten te kunnen maken.
3.1 DNA kopiëren
Terwijl je dit leest zijn duizenden cellen in je lichaam bezig zich te verdubbelen. Dit proces heet celdeling (= mitose). Alles in de cel moet dus verdubbeld worden, óók de informatiedrager DNA. Dit gaat relatief gemakkelijk, omdat de twee strengen van de dubbele helix elkaars tegengestelden zijn: de een is als het ware het negatief van de andere. Overal waar op de ene streng A zit, zit op de andere streng T en overal waar op de ene streng C zit, zit op de andere streng G (en omgekeerd).
Het proces waarbij DNA wordt verdubbeld noemt men DNA-replicatie en gaat als volgt in zijn werk:
- Het DNA wordt afgerold.
- Een enzym (helicase) ritst de twee strengen van de dubbele helix van elkaar door de waterstofbruggen tussen de basen te verbreken:
 (afb. 13)
(afb. 13) - Nucleotide voor nucleotide wordt door een ander enzymcomplex (DNA-polymerase) aan elke losse streng een nieuwe negatieve kopie vastgemaakt, dus A aan T, C aan G en omgekeerd:
 (afb. 14)
(afb. 14) - Het resultaat: twee dubbele strengen, ieder gelijk aan de oorspronkelijke !!
3.2 Productie van eiwitten.
Een chromosoom is ingedeeld in genen. Een gen is een stukje DNA dat de informatie bevat om één bepaald eiwit te kunnen maken (alhoewel sommige genen de informatie voor verschillende eiwitten bevatten). Zon 85 à 97% van ons DNA is echter geen gen en zorgt dus niet voor eiwitten. We noemen dit intergeen DNA of junk-DNA. De functie van een groot deel van dit junk-DNA is nog niet bekend, maar de wetenschap is volop bezig om ook dit raadsel te ontsluieren.
Een eiwit is een heel lang polymeer. Dat is een molecuul opgebouwd uit vele, sterk op elkaar lijkende stukjes.
Alle eiwitten bestaan uit aminozuren die allemaal eenzelfde basisstructuur hebben: aan één centraal C-atoom bevinden zich een amino(NH2)-groep en een carboxyl (COOH)-groep die voor alle aminozuren identiek zijn. Het verschil tussen de aminozuren zit hem in de restgroep, hieronder weergegeven met een R.
 (afb. 15)
(afb. 15)Van die aminozuren bestaan er maar een twintigtal verschillende, steeds met dezelfde basis, maar met een andere restgroep:
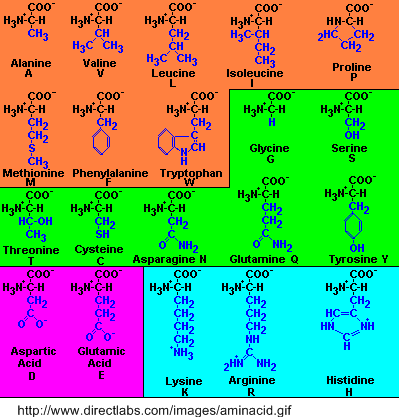 (afb. 16)
(afb. 16)Door die aminozuren in een bepaalde volgorde en aantal aan elkaar te koppelen kun je een bijna oneindig aantal verschillende eiwitten bouwen. Daarvoor moeten steeds (peptide)bindingen gemaakt worden tussen de aminogroep van het ene aminozuur en de carboxylgroep van het volgende.
Zo kun je die aminozuren makkelijk tot een lange keten aaneenrijgen:
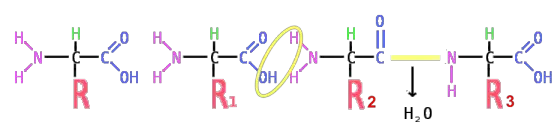 (afb. 17)
(afb. 17)3.3 Informatie voor eiwitten uit DNA halen.
Zoals je nu weet zijn er voor alle processen die zich in ons lichaam afspelen eiwitten nodig en is het DNA het 'bouwplan' voor deze eiwitten. Het bouwen van een eiwit is echter een hele bedoening en de celkern, waar het DNA zich bevindt, is daar veel te klein voor. Eiwitten worden dus ergens anders in de cel gebouwd, op plaatsen die ribosomen heten. Het DNA kan de celkern echter niet verlaten. Daarom moet er, telkens als er een eiwit gebouwd moet worden, een stukje DNA (verantwoordelijk voor dat eiwit) gekopieerd worden. Dat stukje kan de celkern wel verlaten en naar het ribosoom gaan.
Je kan het je als volgt voorstellen: het DNA is een grote kast vol met bouwplannen. Wanneer we bijvoorbeeld een venster (= een eiwit) gaan bouwen, hebben we niet heel die papierwinkel nodig, maar enkel het plan (= het gen) voor dat venster. We kopiëren dus dat plan en gaan ermee naar de bouwwerf (= het ribosoom), waar het venster gebouwd wordt.
Maar hoe gaat dat hele kopieerproces nu eigenlijk in zijn werk?
Allereerst wordt het betreffende stukje DNA (verantwoordelijk voor dat eiwit) opengeritst.
Van dat stuk van één van de strengen wordt dan een (negatieve) kopie gemaakt, ongeveer zoals dat ook gebeurde voor de verdubbeling van DNA (zie § 3.1). Dit wordt ook wel 'transcriptie' genoemd.
Er zijn echter drie belangrijke verschillen:
- Er wordt maar één streng gekopieerd. Deze kopiestreng noemen mRNA (messenger-RNA).
- Voor de ruggengraat van deze kopiestreng wordt geen Desoxyribose (de D van DNA, "des" = ontdaan van, "oxy"= zuurstof) meer gebruikt,
maar Ribose, zodat de streng nu RNA heet (Ribo Nucleic Acid)
 (afb. 18)
(afb. 18) - Als complementaire base voor adenine wordt nu niet meer thymine gebruikt, maar uracil.
 (afb. 19)
(afb. 19)
Langs de RNA-streng kun je als het ware aan de stikstofbasen een geheimschrift aflezen, bijv. G C A G C G G U enz.
 (afb. 20)
(afb. 20)Elk groepje van drie van die "letters" op het mRNA heet een codon.
(Je zou dit een beetje kunnen vergelijken met een "byte" uit de computerwereld, die elk bestaan uit 8 "bits")
Er zijn vier letters beschikbaar (C, A, G en U) waarmee je dus 4 x 4 x 4 = 64 combinaties van 3 kunt maken.
64 mogelijke combinaties: dat zijn er meer dan genoeg voor die 20 aminozuren, dus er zijn aminozuren die door meer dan 1 codon aangeduid kunnen worden.
Er is ook een codon dat enkel bij de start voorkomt (het zgn. startcodon: bij de mens en alle andere eukaryoten is dit AUG) en drie codons die het einde van het hele proces aangeven (de zgn. stopcodons UAA, UAG en UGA).
Een volledige lijst van welke codons voor welk aminozuur coderen vind je op Wikipedia.
Hoe dit alles werkt:
GCA is code voor "plak hier het aminozuur alanine". Om dat voor elkaar te krijgen wordt aan een alaninemolecuul een ander klein stukje RNA met maar drie "letters" vastgemaakt. Zo'n stukje RNA heet tRNA (transfer-RNA of ook wel transport-RNA). Dat tRNA moet even op het mRNA gepast worden. De code op het tRNA moet dus precies het negatief van het codon op het mRNA zijn, en heet daarom "anticodon".
 (afb. 21)
(afb. 21)Hierboven weer als voorbeeld alanine: op het mRNA werd hiervoor gecodeerd met GCA, dat wil zeggen dat het tRNA van alanine een anticodon moet hebben met de (complementaire) basen CGU.
Aan het volgende mRNA-codon wordt weer een (ander) tRNA met een (zelfde of een ander) aminozuur vastgemaakt.
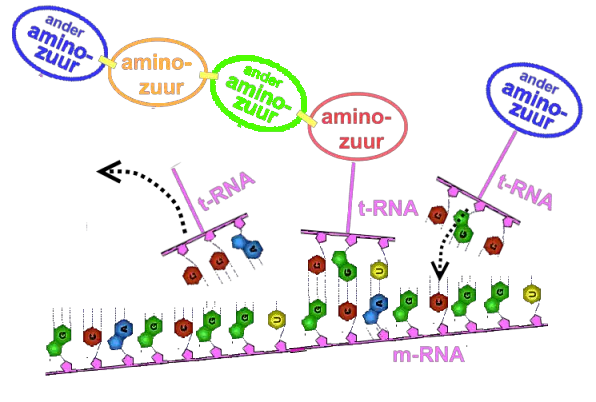 (afb. 22)
(afb. 22)De aminozuren worden aan elkaar gekoppeld zoals je zag in § 3.2, een volgend aminozuur wordt gezocht, gekoppeld, etc, en zo ontstaat een hele keten van aminozuren, een eiwit. Intussen laten de overbodig geworden stukjes tRNA weer los. Dit gaat zo door totdat er op het mRNA een stopcodon gevonden wordt. Dan is het eiwit compleet. Dit hele proces wordt ook wel 'translatie' genoemd.
Terzijde: De nu complete eiwitketen zal zich hierna opvouwen tot een compacte kluwen, waardoor het eiwit zijn specifieke werking krijgt. Een heel klein beetje meer daarover lees je in het Foldingtopic.
In de bovenstaande microcursus kreeg je in het kort een overzicht van wat DNA is, hoe het in elkaar zit en hoe het functioneert om leven mogelijk te maken. Uiteraard is hierover véél meer te vertellen. Over enige tijd hopen we te kunnen komen met een minicursus, die op dit fenomeen véél dieper zal ingaan.